SCPで始めるAllenNLP ~SCPオブジェクトクラス分類~
21 Dec 2019はじめに
この記事は公立はこだて未来大学 Advent Calendar 2019 part2の21日目の記事です。 昨日の記事はkmdkukさんのテック系Podcastのススメでした。 裏番組(Part1)はohayotaさんが書くようです。
ほぼ前にLT会でやったネタの使い回しですが書いていきます
SCPとは
![]() SCPロゴ ©Aelanna CC BY-SA 3.0
SCPロゴ ©Aelanna CC BY-SA 3.0
御存知SFホラー系創作コミュニティサイト「SCP-Foundation」
物体・生物・概念を問わず様々な創作都市伝説が報告書形式で書かれています
「目を離すと動く石像」「駄洒落にツッコミを入れるトマト」「ねこですよろしくおねがいします」あたりが有名でしょうか。 おい待て!リンクから記事を読み始めるんじゃあない!後にしろ!
SCPの世界では「SCP財団」がオブジェクトと呼ばれる特異存在を収容しています。 そして、各オブジェクトにはオブジェクトクラスという収容難易度が割り当てられています。
大半のオブジェクトは下の3つに分類されます。
-
Safe: 収容手順が確立されておりよほどのことが無い限り脱走・紛失の心配はない
-
Euclid: 知性を持っているなどの不安要素があり、管理に注意が必要
-
Keter: 収容が困難かつ、収容違反による甚大な被害の恐れがある
また、報告書には必ず特別収容プロトコルという収容のためのマニュアルのような文章が書いてあります。
データセットとタスク
SCP-JP及び本家SCPの翻訳版を用います
タスクは「特別収容プロトコルの文章から、基本オブジェクトクラス(Safe, Euclid, Keter)を予測する」こと
「ロッカーで保管」「特別収容の必要はありません」とか書いてあるとSafeっぽいし、 「人型」「見た人の記憶を消せ」とか書いてあればEuclid以上、 「行方不明」「できるだけ早く破壊しなければなりません」なんて書いてあったら間違いなくKeterですね。
ただ収容手順が確立してさえれば、やたら厳重でも案外safeだったりするので、そのへんをどう捌けるかが重要そう
スクレイピング
“http://ja.scp-wiki.net/scp-{0:03d}”.format(index) って感じでfor文回して直接取りに行く。アクセス間隔はちゃんと空けましょう。データセットにはオブジェクト番号/オブジェクトクラス/特別収容プロトコルを収集していきます。
特別収容プロトコルは「特別収容プロトコル:」~「説明:」で大体取れるけど、例外も多いので適宜例外処理+目測で推敲します。データのかさまし+文章を短くして学習しやすくするために、複数の段落になっているプロトコルは別のデータに分割します。それでも128単語以上になる文は超過部分を切り捨てます。
オブジェクトクラスは、記事下部の記事タグをBeautifulSoupなどで取ります
csvやjsonだと「,」や「”」が引っかかったりしてやりづらいのでtsvで保存するのがオススメ
そんなこんなでデータが計8282件集まりました。すっっっっっくな
文章長ごとのデータ数と各ラベルごとのデータ数のグラフです。
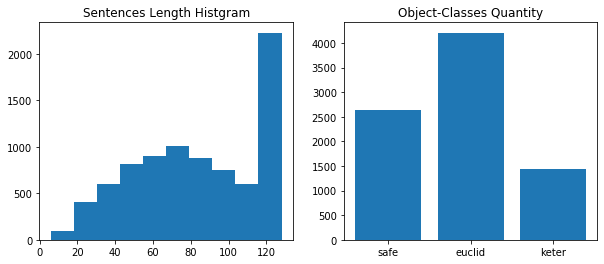
既にオチが読め始めた人もいると思います
モデル
このへんは機械学習用語が多いので斜め読みで
Recurrent convolutional neural networks for text classification
Siwei Lai, Liheng Xu, Kang Liu, Jun Zhao, Chinese Academy of Sciences, China AAAI. 2015.
文書分類のわりと基本的なモデルです。ざっくり書くと、
- 単語埋め込みのシーケンスを双方向RNNに通す
- 各時刻で単語埋め込みとRNN出力を横に連結する
- 連結したものを並べてからMaxPoolingする
- softmax分類器で分類
これを、自然言語特化の機械学習ライブラリであるAllenNLPでやっていきます。 書き方はPyTorchと大した変わりませんが、データローダやモジュール、ユーティリティが豊富です。 ソースコードも読みやすいです、型付きPythonに目を慣らす必要はあるけど…
AllenNLPを使う利点として、ELMoやTransformerなどの自然言語モデルで使われる複雑で強力なモデルやモジュールを簡単に使う/組み込むことができます。 なので、単語埋め込みにELMo、RNNの代わりにTransformerのEncoder(Stacked Self Attention)を使ってみたいと思います。 論文調査が間に合ってないので、実際にこのモデルとタスクに有効なアプローチなのかはわかんないです><
あんまり参考にならないと思うけど一応ハイパーパラメータ並べときます。コードも参照。
- 単語埋め込みの次元数: 1024
- リカレント層の隠れ次元数: 512
- 分類器の線形層の次元数: 1024
- ドロップアウト率: 0.2
バッチサイズ64、学習率1e-4でAdam使いました。
コード
学習用のコードはGoogle Colaboratoryで公開しているのでデータセットさえあれば誰でも動かせます。随時更新中。
データセットをGoogleドライブのマイドライブ/datasets/scp/にtrain.tsvとvalid.tsvを置けば、そのまま動かせる…はず…
そのうちスクレイピング用のコードも公開するかもです
結果
どのくらいの精度が出たかのスコアとして以下を用います。
- Prediction: ラベルAだと予測したもののうち本当にAだったものの割合
- Recall: 全てのAのうちAだときちんと予測できたものの割合
- F1-Score: PredictionとRecallの中間のスコア
- Accuracy: ラベルに関わらず、正解できたものの割合
学習は11epochでEarly Stoppingしました。 訓練データのLossが0.88、Accuracyが0.60%でした。
さて、こちらが結果です。
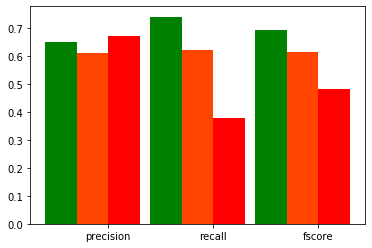
棒グラフは緑がSafeのスコア、オレンジがEuclid、赤がKeterです。 未知データのAccuracyは47%でした。 全体的に散々ですが、特に一番重要なKeterのRecallが低すぎますね。 Focal Lossなどの不均衡データ対策をやったらもう少し上がるのかもしれないです。
そもそも未知データのLossが暴れまくってたのでデータ量も全然足りて無さそうです。 段落よりもっと細かい単位で区切ってかさましした方が良かったかも?
とりあえず、今のままだと大量のKeterオブジェクトがSafe・Euclid判定を受けるので大規模収容違反不可避ですね 時間が空いたらまた再戦したいと思います
まとめ
こうして世界はK-クラスシナリオを迎え、2020年が来ることはありませんでした(Thaumielの音) 明石暁先生の次回作にご期待ください。
明日の記事はやと(と)さんがお送りするようです。